Speech2Gesture
项目定位
这一部分聚焦基于语音素材的骨骼驱动。目标是让数字人在说话时,不只是播放固定动作,而是根据语音、文本和说话人风格生成同步发生的骨骼动作序列。
Speech-driven Gesture Skeletal Animation Audio + Text 6D Rotation Virtual Human
核心思路
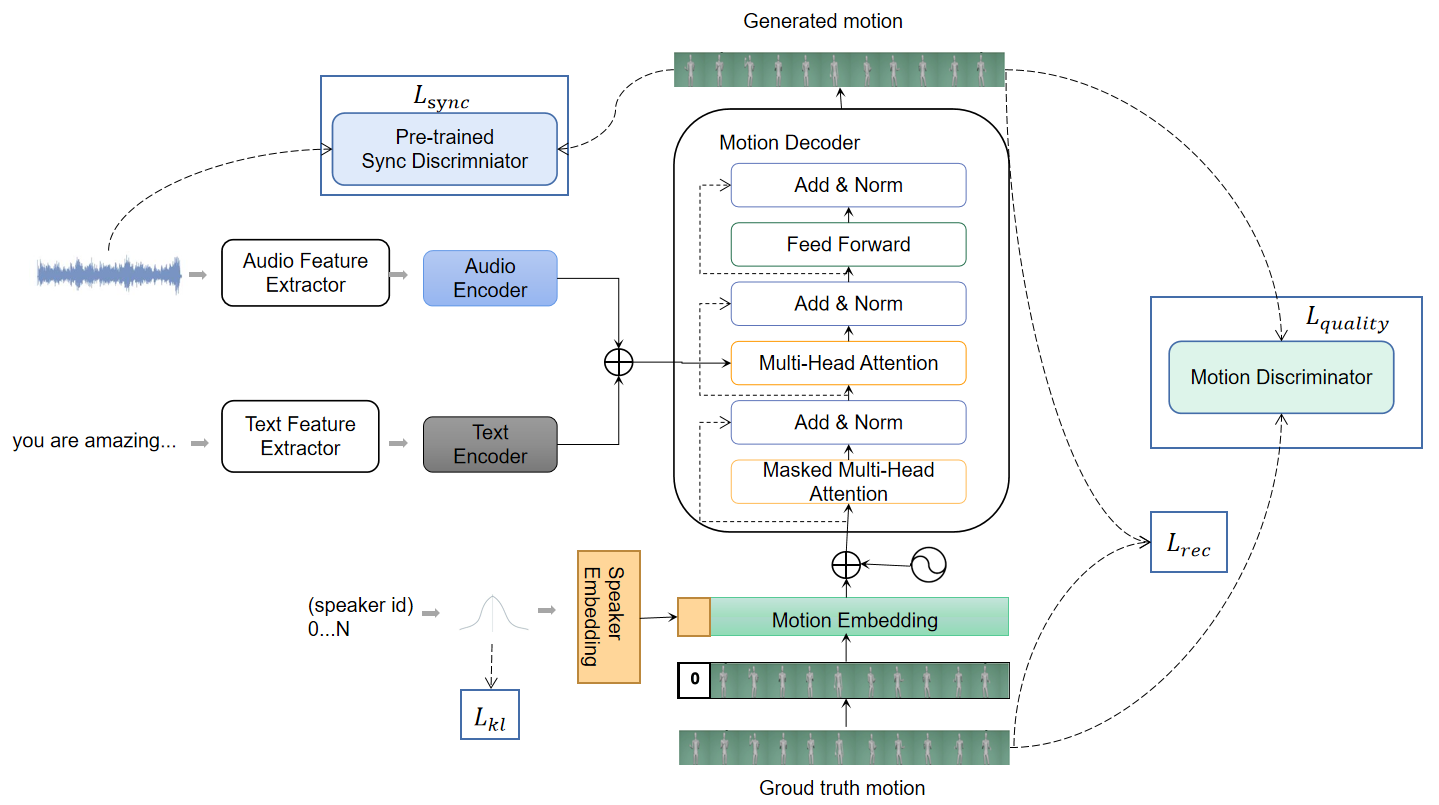
方法图展示了语音特征、文本特征和说话人嵌入如何进入编码器与动作解码器,以及同步判别器、质量判别器和重建损失如何共同约束生成结果。
- 模型主链路是:语音特征、文本特征和说话人嵌入共同条件化动作解码器,逐帧生成骨骼动作序列,再由同步、质量和重建相关约束共同拉住生成质量。
- 输入侧同时使用语音、文本和说话人信息,而不是只依赖单一音频特征。
- 模型重点解决动作静态、抖动、不连续和语义相关性不足几个问题。
- 动作用 6D rotation 表示,并结合 Slerp 后处理,减少欧拉角表示带来的跳变和抖动。
- 编码器部分同时尝试了时间维融合和特征维融合两种音频文本融合方式,解码器负责逐帧生成动作序列。
结果视频
结果视频展示了语音驱动骨骼动作的实际输出效果,可直接观察动作节奏、上肢摆动和整体连贯性。